
Lorie and Fisher. Big Data circa 1960.
For much of its history as a discipline, economics has been trapped in a Small Data paradigm. Macroeconomists analyzed output and inflation using annual or quarterly data spanning several decades at best. Microeconomic datasets varied more widely in size, but even large cross-sectional surveys were rarely big by today’s standards. While the econometric methods developed were often highly sophisticated, they generally focused more on estimation of structural equations and testing economic theories than on prediction. Searching for patterns outside a theoretical framework was largely dismissed as data mining.
Thanks to the efforts of Jim Lorie and Larry Fisher in developing the CRSP database at Chicago in the 1960s, financial economists have enjoyed a relative wealth of high-quality data. Furthermore, there has always been an interest in prediction within finance. However, empirical stock market research, at least in academia, has typically focused on discovering anomalies in returns by sorting stocks along a single dimension such as market capitalization or book-to-market ratio. Occasionally researchers would double or even triple sort stocks into portfolios, but generally would not explore additional dimensions. Haugen and Baker (1996), which used a few dozen variables to predict stock returns, was a notable exception. More distressingly, the result of generations of researchers “spinning” the CRSP tapes in a collective data mining exercise was that many empirical findings discovered about stock returns were unreliable out-of-sample.
In recent years the data used in economic research have grown tremendously in both volume and variety. High frequency financial datasets are notable examples. Others include unstructured data including text from news and social media and audio from management conference calls discussing company earnings. While being somewhat late to the party, economists have increasingly adopted a Big Data paradigm. Reflecting these developments, NBER devoted it’s summer institute last year to Econometric Methods for High-Dimensional Data.
More evidence for the growing interest of economists in Big Data comes from Hal Varian’s article Big Data: New Tricks for Econometrics in the latest issue of the Journal of Economic Perspectives. Varian, a long-time economics professor at Berkeley before becoming the chief economist at Google, writes that “my standard advice to graduate students these days is go to the computer science department and take a class in machine learning.”
He makes a number of observations including (1) economists immediately think of a linear or logistic regression when confronted with a prediction problem despite there often being better models, (2) economists have not been as explicit as machine learning people about quantifying model complexity costs, and (3) cross-validation is a more realistic measure of performance than in-sample measures commonly used in economics. While these judgments are perhaps a bit too sweeping, they raise important issues that I will explore in future posts, particularly from the perspective of a financial markets investor.

![[1]\hspace{0.5cm} R_t = E_{t-1}(R_t) + \epsilon_t](https://s0.wp.com/latex.php?latex=%5B1%5D%5Chspace%7B0.5cm%7D+R_t+%3D+E_%7Bt-1%7D%28R_t%29+%2B+%5Cepsilon_t&bg=ffffff&fg=333333&s=0&c=20201002)
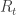 is return in period t,
is return in period t,  is expected return in period t conditional on the information available at t-1, and
is expected return in period t conditional on the information available at t-1, and 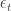 is unexpected return.
is unexpected return. is to use a linear function of a predictor variable
is to use a linear function of a predictor variable  . Thus, we have
. Thus, we have![[2]\hspace{0.5cm} \mu_t = \beta x_t + \nu_t](https://s0.wp.com/latex.php?latex=%5B2%5D%5Chspace%7B0.5cm%7D+%5Cmu_t+%3D+%5Cbeta+x_t+%2B+%5Cnu_t&bg=ffffff&fg=333333&s=0&c=20201002)
 is an error term. We want to run a linear regression, but since
is an error term. We want to run a linear regression, but since  is unobservable, we must first identify observable proxies. The usual approach, of course, is to use realized returns
is unobservable, we must first identify observable proxies. The usual approach, of course, is to use realized returns  to proxy for expected returns
to proxy for expected returns 

